When More Cores Means Less Speed: Debugging PyTorch with Valgrind on ARM
If you’ve ever tried to debug a PyTorch program on an ARM64 system using
Valgrind, you might have stumbled on something really
odd: “Why does it take so long?”. And if you’re like us, you would probably try
to run it locally, on a Raspberry pi, to see what’s going on… And the madness
begins!
TL;DR, as you probably figured out from the title of this post, it’s a
counter-intuitive experience: the more cores your machine has, the slower your
(torch) code seems to run under Valgrind. Shouldn’t more cores mean more speed?
Let’s dive into why that’s not always the case ;)
The background
In an effort to improve our testing infrastructure for
vAccel and make it more robust, we
started cleaning up our examples, unifying the build & test scripts and started
adding more elaborate test cases for both the library and the plugins.
Valgrind provides a quite decent experience for this, especially to catch
multi-arch errors, memory leaks and dangling pointers (something quite common
when writing in C :D).
The issue
While adding the Valgrind mode of execution in our tests for the vAccel
plugins, we noticed something really weird in the
Torch
case. The test was taking forever!
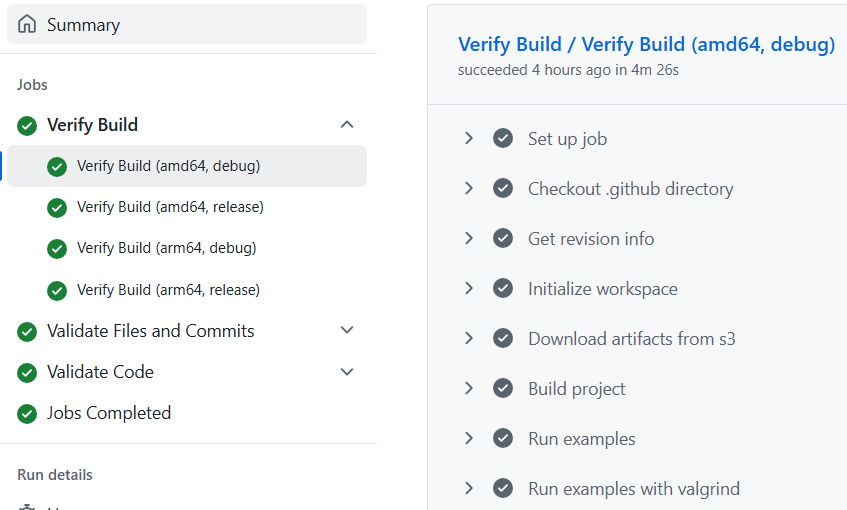
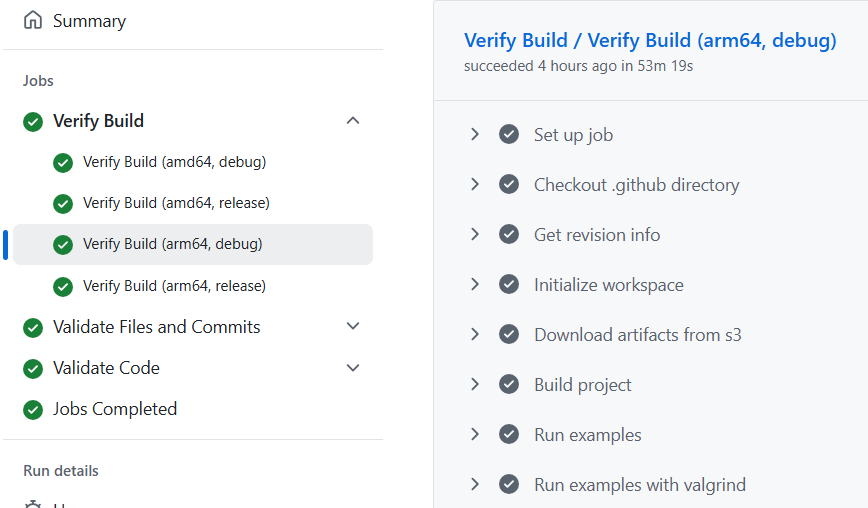
Specifically, while the equivalent amd64 was taking roughly 4 and a half
minutes (Figure 1), the arm64 run was taking nearly an hour (53 minutes) –
see Figure 2.
Debugging
The first thing that came to mind was that there’s something wrong with our
infrastructure. We run self-hosted Github runners, with custom container images
that support the relevant software components we need for each plugin/case. We
run those on our infra, a set of VMs running on top of diverse low-end
bare-metal machines, both amd64 and arm64. The arm64 runners run on a
couple of Jetson AGX Orins, with 8 cores and 32GB of RAM.
And what’s the first thing to try (especially when debugging on arm64? A
Raspberry Pi of course!
So getting the runner container image on a Raspberry Pi 5, with 8GB of RAM, spinning up the container, building the library and the plugin, all took roughly 10 minutes. And we’re ready for the test:
# ninja run-examples-valgrind -C build-container
ninja: Entering directory `build-container'
[0/1] Running external command run-examples-valgrind (wrapped by meson to set env)
Arch is 64bit : true
[snipped]
Running examples with plugin 'libvaccel-torch.so'
+ valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/develop/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --suppressions=/home/ananos/develop/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/torch_inference /home/runner/artifacts/share/vaccel/images/example.jpg https://s3.nbfc.io/torch/mobilenet.pt /home/runner/artifacts/share/vaccel/labels/imagenet.txt
==371== Memcheck, a memory error detector
==371== Copyright (C) 2002-2024, and GNU GPL'd, by Julian Seward et al.
==371== Using Valgrind-3.25.1 and LibVEX; rerun with -h for copyright info
==371== Command: /home/runner/artifacts/bin/torch_inference /home/runner/artifacts/share/vaccel/images/example.jpg https://s3.nbfc.io/torch/mobilenet.pt /home/runner/artifacts/share/vaccel/labels/imagenet.txt
==371==
2025.07.10-20:48:01.91 - <debug> Initializing vAccel
2025.07.10-20:48:01.93 - <info> vAccel 0.7.1-9-b175578f
2025.07.10-20:48:01.93 - <debug> Config:
2025.07.10-20:48:01.93 - <debug> plugins = libvaccel-torch.so
2025.07.10-20:48:01.93 - <debug> log_level = debug
2025.07.10-20:48:01.93 - <debug> log_file = (null)
2025.07.10-20:48:01.93 - <debug> profiling_enabled = false
2025.07.10-20:48:01.93 - <debug> version_ignore = false
2025.07.10-20:48:01.94 - <debug> Created top-level rundir: /run/user/0/vaccel/ZpNkGT
2025.07.10-20:48:47.87 - <info> Registered plugin torch 0.2.1-3-0b1978fb
[snipped]
2025.07.10-20:48:48.07 - <debug> Downloading https://s3.nbfc.io/torch/mobilenet.pt
2025.07.10-20:48:53.18 - <debug> Downloaded: 2.4 KB of 13.7 MB (17.2%) | Speed: 474.96 KB/sec
2025.07.10-20:48:54.93 - <debug> Downloaded: 13.7 MB of 13.7 MB (100.0%) | Speed: 2.01 MB/sec
2025.07.10-20:48:54.95 - <debug> Download completed successfully
2025.07.10-20:48:55.04 - <debug> session:1 Registered resource 1
2025.07.10-20:48:56.37 - <debug> session:1 Looking for plugin implementing torch_jitload_forward operation
2025.07.10-20:48:56.37 - <debug> Returning func from hint plugin torch
[snipped]
CUDA not available, running in CPU mode
Success!
Result Tensor :
Output tensor => type:7 nr_dims:2
size: 4000 B
Prediction: banana
[snipped]
==371== HEAP SUMMARY:
==371== in use at exit: 339,636 bytes in 3,300 blocks
==371== total heap usage: 1,779,929 allocs, 1,776,629 frees, 405,074,676 bytes allocated
==371==
==371== LEAK SUMMARY:
==371== definitely lost: 0 bytes in 0 blocks
==371== indirectly lost: 0 bytes in 0 blocks
==371== possibly lost: 0 bytes in 0 blocks
==371== still reachable: 0 bytes in 0 blocks
==371== suppressed: 339,636 bytes in 3,300 blocks
==371==
==371== For lists of detected and suppressed errors, rerun with: -s
==371== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 3160 from 3160)
+ valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/develop/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --suppressions=/home/ananos/develop/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/classify /home/runner/artifacts/share/vaccel/images/example.jpg 1 https://s3.nbfc.io/torch/mobilenet.pt
==376== Memcheck, a memory error detector
==376== Copyright (C) 2002-2024, and GNU GPL'd, by Julian Seward et al.
==376== Using Valgrind-3.25.1 and LibVEX; rerun with -h for copyright info
==376== Command: /home/runner/artifacts/bin/classify /home/runner/artifacts/share/vaccel/images/example.jpg 1 https://s3.nbfc.io/torch/mobilenet.pt
==376==
2025.07.10-20:54:37.78 - <debug> Initializing vAccel
2025.07.10-20:54:37.80 - <info> vAccel 0.7.1-9-b175578f
2025.07.10-20:54:37.80 - <debug> Config:
2025.07.10-20:54:37.80 - <debug> plugins = libvaccel-torch.so
2025.07.10-20:54:37.80 - <debug> log_level = debug
2025.07.10-20:54:37.80 - <debug> log_file = (null)
[snipped]
2025.07.10-20:55:30.78 - <debug> Found implementation in torch plugin
2025.07.10-20:55:30.78 - <debug> [torch] Loading model from /run/user/0/vaccel/zazTtc/resource.1/mobilenet.pt
CUDA not available, running in CPU mode
2025.07.10-21:01:14.77 - <debug> [torch] Prediction: banana
classification tags: banana
[snipped]
2025.07.10-21:01:23.92 - <debug> Unregistered plugin torch
==376==
==376== HEAP SUMMARY:
==376== in use at exit: 341,280 bytes in 3,304 blocks
==376== total heap usage: 3,167,523 allocs, 3,164,219 frees, 534,094,402 bytes allocated
==376==
==376== LEAK SUMMARY:
==376== definitely lost: 0 bytes in 0 blocks
==376== indirectly lost: 0 bytes in 0 blocks
==376== possibly lost: 0 bytes in 0 blocks
==376== still reachable: 0 bytes in 0 blocks
==376== suppressed: 341,280 bytes in 3,304 blocks
==376==
==376== For lists of detected and suppressed errors, rerun with: -s
==376== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 3161 from 3161)
+ set +x
Note: We’ll talk about the suppressions a bit later
The test took roughly 13 minutes. At this point, we were scratching our heads.
Why would a high-end Jetson Orin, with way more cores and RAM, perform so much
worse under Valgrind than a humble Raspberry Pi? Time to dig deeper into what’s
really going on under the hood…
The Surprise
When the results came in, the numbers were still striking: the same
Valgrind-wrapped Torch test that took almost an hour on our Jetson Orin
finished in just 13 minutes on the Raspberry Pi. The Pi, with far less RAM and
CPU muscle, still managed to outperform the Orin by a wide margin under these
specific conditions.
This result was the definition of counter-intuitive. Everything we know about hardware says the Orin should wipe the floor with the Pi. Yet, here we were, staring at the Pi’s prompt, wondering if we’d missed something obvious.
Digging Deeper: What’s Really Happening?
So, what’s going on? Why does a high-end, multi-core ARM system get crushed by
a humble Pi in this scenario? The answer lies at the intersection of Valgrind,
multi-threaded workloads, and the quirks of the ARM64 ecosystem.
Thread Count: The Double-Edged Sword
Modern CPUs, especially high-end ARM chips like the Orin, have lots of cores, and frameworks like PyTorch are eager to use them all. By default, PyTorch will spawn as many threads as it thinks your system can handle, aiming for maximum parallelism.
But Valgrind, which works by instrumenting every memory access and
synchronizing thread activity to catch bugs, doesn’t scale gracefully with
thread count. In fact:
- Each additional thread multiplies
Valgrind’s overhead. More threads mean more context switches, more synchronization, and more internal bookkeeping. - On platforms where
Valgrind’s threading support is less mature (like aarch64), this overhead can balloon out of control. - On the Raspberry Pi, with its modest core count, PyTorch only spawns a
handful of threads. But on the Orin, with many more cores, PyTorch ramps up
the thread count—and
Valgrind’s overhead explodes.
The ARM64 Valgrind Quirk
The arm64 port of Valgrind is still catching up to its amd64 sibling in
terms of optimizations and robustness. Some operations, especially those
involving threads and memory, are simply slower to emulate and track on arm64.
This compounds the thread explosion problem, making high-core-count systems
paradoxically slower under Valgrind.
Dealing with library suppressions on arm64 with Valgrind
For instance, when running applications that rely on specific libraries under
Valgrind on arm64 systems, developers frequently encounter a barrage of
memory-related warnings and errors. Many of these issues are not actual bugs in
your code, but rather artifacts of how these libraries manage memory
internally, or limitations in Valgrind’s emulation on such architectures.
For instance, OpenSSL is known for its custom memory management strategies. It
often allocates memory statically or uses platform-specific tricks, which can
confuse Valgrind’s memory checker. For example, you might see reports of
“still reachable” memory or even “definitely lost” memory at program exit.
In reality, much of this memory is intentionally held for the lifetime of the
process—such as global tables or the state for the random number generator.
These are not leaks in the conventional sense, but Valgrind will still flag
them, especially if you run with strict leak checking enabled.
On arm64 platforms, the situation can be further complicated. Valgrind may
not fully emulate every instruction used by the specific library. This can lead
to false positives, such as uninitialized value warnings, or even more dramatic
errors like SIGILL (illegal instruction) if Valgrind encounters an
unsupported operation.
It’s not uncommon to see a flood of warnings that are, in practice, harmless or simply not actionable unless you’re developing for that specific library itself.
To manage this noise and focus on real issues in our application, we use
Valgrind’s suppression mechanism. Suppression files allow us
to tell Valgrind to ignore specific known issues, so we can zero in on genuine
bugs in our own code.
Suppression entries are typically matched by library object names, so on
arm64 we use patterns like /usr/lib/aarch64-linux-gnu/libssh.so* or
obj:*libc10*.so*, obj:*libtorch*.so*.
An example suppression snippet (valgrind.supp) looks like the following:
[...]
{
suppress_libtorch_leaks
Memcheck:Leak
match-leak-kinds: reachable,possible
...
obj:*libtorch*.so*
}
{
suppress_libtorch_ovelaps
Memcheck:Overlap
...
obj:*libtorch*.so*
}
[...]
It’s important to note that not all problems can be suppressed away. For
example, if Valgrind encounters a truly unsupported instruction and throws a
SIGILL, a suppression file won’t help; you may need to update Valgrind or avoid
that code path. Still, for the majority of benign memory warnings from OpenSSL
or Torch, well-crafted suppressions keeps our Valgrind output manageable
and meaningful.
Debug Symbol Overhead
Another factor: large binaries with lots of debug symbols (common in deep
learning stacks) can cause Valgrind to spend an inordinate amount of time just
parsing and managing symbol information. The more complex the binary and its
dependencies, the longer the startup and runtime overhead. Again, amplified on
arm64.
Lessons Learned (and What You Can Do)
Limit Thread Count: When running under Valgrind, explicitly set PyTorch to
use a single thread OMP_NUM_THREADS=1. This alone can make a world of
difference.
Test Small: Use the smallest possible model and dataset for Valgrind runs.
Save the big workloads for native or lighter-weight profiling tools.
Expect the Unexpected: Don’t assume that “bigger is better” when debugging
with Valgrind – sometimes, less really is more!
Profile Performance Separately: Use Valgrind for correctness and bug-hunting,
not for benchmarking or performance profiling.
And here’s the full snippet of the test, on a runner VM on the Jetson Orin, taking less than 6 minutes:
$ ninja run-examples-valgrind -C build
ninja: Entering directory `build'
[0/1] Running external command run-examples-valgrind (wrapped by meson to set env)
Arch is 64bit : true
Default config dir : /home/ananos/vaccel-plugin-torch/scripts/common/config
Package : vaccel-torch
Package config dir : /home/ananos/vaccel-plugin-torch/scripts/config
Package lib dir : /home/ananos/vaccel-plugin-torch/build/src
vAccel prefix : /home/runner/artifacts
vAccel lib dir : /home/runner/artifacts/lib/aarch64-linux-gnu
vAccel bin dir : /home/runner/artifacts/bin
vAccel share dir : /home/runner/artifacts/share/vaccel
Running examples with plugin 'libvaccel-torch.so'
+ eval valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --fair-sched=no --suppressions=/home/ananos/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/torch_inference /home/runner/artifacts/share/vaccel/images/example.jpg https://s3.nbfc.io/torch/mobilenet.pt /home/runner/artifacts/share/vaccel/labels/imagenet.txt
+ valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --fair-sched=no --suppressions=/home/ananos/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/torch_inference /home/runner/artifacts/share/vaccel/images/example.jpg https://s3.nbfc.io/torch/mobilenet.pt /home/runner/artifacts/share/vaccel/labels/imagenet.txt
==1655== Memcheck, a memory error detector
==1655== Copyright (C) 2002-2024, and GNU GPL'd, by Julian Seward et al.
==1655== Using Valgrind-3.25.1 and LibVEX; rerun with -h for copyright info
==1655== Command: /home/runner/artifacts/bin/torch_inference /home/runner/artifacts/share/vaccel/images/example.jpg https://s3.nbfc.io/torch/mobilenet.pt /home/runner/artifacts/share/vaccel/labels/imagenet.txt
==1655==
2025.07.10-20:06:28.83 - <debug> Initializing vAccel
2025.07.10-20:06:28.85 - <info> vAccel 0.7.1-9-b175578f
2025.07.10-20:06:28.86 - <debug> Config:
2025.07.10-20:06:28.86 - <debug> plugins = libvaccel-torch.so
2025.07.10-20:06:28.86 - <debug> log_level = debug
2025.07.10-20:06:28.86 - <debug> log_file = (null)
2025.07.10-20:06:28.86 - <debug> profiling_enabled = false
2025.07.10-20:06:28.86 - <debug> version_ignore = false
2025.07.10-20:06:28.87 - <debug> Created top-level rundir: /run/user/1000/vaccel/P01ae4
2025.07.10-20:07:27.35 - <info> Registered plugin torch 0.2.1-3-0b1978fb
2025.07.10-20:07:27.35 - <debug> Registered op torch_jitload_forward from plugin torch
2025.07.10-20:07:27.35 - <debug> Registered op torch_sgemm from plugin torch
2025.07.10-20:07:27.35 - <debug> Registered op image_classify from plugin torch
2025.07.10-20:07:27.35 - <debug> Loaded plugin torch from libvaccel-torch.so
2025.07.10-20:07:27.39 - <debug> Initialized resource 1
Initialized model resource 1
2025.07.10-20:07:27.39 - <debug> New rundir for session 1: /run/user/1000/vaccel/P01ae4/session.1
2025.07.10-20:07:27.39 - <debug> Initialized session 1
Initialized vAccel session 1
2025.07.10-20:07:27.40 - <debug> New rundir for resource 1: /run/user/1000/vaccel/P01ae4/resource.1
2025.07.10-20:07:27.62 - <debug> Downloading https://s3.nbfc.io/torch/mobilenet.pt
2025.07.10-20:07:33.90 - <debug> Downloaded: 555.7 KB of 13.7 MB (4.0%) | Speed: 88.84 KB/sec
2025.07.10-20:07:36.78 - <debug> Downloaded: 13.7 MB of 13.7 MB (100.0%) | Speed: 1.50 MB/sec
2025.07.10-20:07:36.80 - <debug> Download completed successfully
2025.07.10-20:07:36.94 - <debug> session:1 Registered resource 1
2025.07.10-20:07:38.16 - <debug> session:1 Looking for plugin implementing torch_jitload_forward operation
2025.07.10-20:07:38.16 - <debug> Returning func from hint plugin torch
2025.07.10-20:07:38.16 - <debug> Found implementation in torch plugin
2025.07.10-20:07:38.16 - <debug> [torch] session:1 Jitload & Forward Process
2025.07.10-20:07:38.16 - <debug> [torch] Model: /run/user/1000/vaccel/P01ae4/resource.1/mobilenet.pt
2025.07.10-20:07:38.17 - <debug> [torch] Loading model from /run/user/1000/vaccel/P01ae4/resource.1/mobilenet.pt
CUDA not available, running in CPU mode
Success!
Result Tensor :
Output tensor => type:7 nr_dims:2
size: 4000 B
Prediction: banana
2025.07.10-20:08:39.93 - <debug> session:1 Unregistered resource 1
2025.07.10-20:08:39.94 - <debug> Released session 1
2025.07.10-20:08:39.94 - <debug> Removing file /run/user/1000/vaccel/P01ae4/resource.1/mobilenet.pt
2025.07.10-20:08:39.95 - <debug> Released resource 1
2025.07.10-20:08:48.91 - <debug> Cleaning up vAccel
2025.07.10-20:08:48.91 - <debug> Cleaning up sessions
2025.07.10-20:08:48.91 - <debug> Cleaning up resources
2025.07.10-20:08:48.91 - <debug> Cleaning up plugins
2025.07.10-20:08:48.92 - <debug> Unregistered plugin torch
==1655==
==1655== HEAP SUMMARY:
==1655== in use at exit: 304,924 bytes in 3,290 blocks
==1655== total heap usage: 1,780,098 allocs, 1,776,808 frees, 406,800,553 bytes allocated
==1655==
==1655== LEAK SUMMARY:
==1655== definitely lost: 0 bytes in 0 blocks
==1655== indirectly lost: 0 bytes in 0 blocks
==1655== possibly lost: 0 bytes in 0 blocks
==1655== still reachable: 0 bytes in 0 blocks
==1655== suppressed: 304,924 bytes in 3,290 blocks
==1655==
==1655== For lists of detected and suppressed errors, rerun with: -s
==1655== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 3153 from 3153)
+ [ 1 = 1 ]
+ eval valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --fair-sched=no --suppressions=/home/ananos/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/classify /home/runner/artifacts/share/vaccel/images/example.jpg 1 https://s3.nbfc.io/torch/mobilenet.pt
+ valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes --errors-for-leak-kinds=all --max-stackframe=3150000 --keep-debuginfo=yes --error-exitcode=1 --suppressions=/home/ananos/vaccel-plugin-torch/scripts/common/config/valgrind.supp --main-stacksize=33554432 --max-stackframe=4000000 --fair-sched=no --suppressions=/home/ananos/vaccel-plugin-torch/scripts/config/valgrind.supp /home/runner/artifacts/bin/classify /home/runner/artifacts/share/vaccel/images/example.jpg 1 https://s3.nbfc.io/torch/mobilenet.pt
==1657== Memcheck, a memory error detector
==1657== Copyright (C) 2002-2024, and GNU GPL'd, by Julian Seward et al.
==1657== Using Valgrind-3.25.1 and LibVEX; rerun with -h for copyright info
==1657== Command: /home/runner/artifacts/bin/classify /home/runner/artifacts/share/vaccel/images/example.jpg 1 https://s3.nbfc.io/torch/mobilenet.pt
==1657==
2025.07.10-20:08:50.40 - <debug> Initializing vAccel
2025.07.10-20:08:50.42 - <info> vAccel 0.7.1-9-b175578f
2025.07.10-20:08:50.42 - <debug> Config:
2025.07.10-20:08:50.42 - <debug> plugins = libvaccel-torch.so
2025.07.10-20:08:50.42 - <debug> log_level = debug
2025.07.10-20:08:50.42 - <debug> log_file = (null)
2025.07.10-20:08:50.42 - <debug> profiling_enabled = false
2025.07.10-20:08:50.42 - <debug> version_ignore = false
2025.07.10-20:08:50.43 - <debug> Created top-level rundir: /run/user/1000/vaccel/73XJNT
2025.07.10-20:09:48.93 - <info> Registered plugin torch 0.2.1-3-0b1978fb
2025.07.10-20:09:48.93 - <debug> Registered op torch_jitload_forward from plugin torch
2025.07.10-20:09:48.93 - <debug> Registered op torch_sgemm from plugin torch
2025.07.10-20:09:48.93 - <debug> Registered op image_classify from plugin torch
2025.07.10-20:09:48.93 - <debug> Loaded plugin torch from libvaccel-torch.so
2025.07.10-20:09:48.94 - <debug> New rundir for session 1: /run/user/1000/vaccel/73XJNT/session.1
2025.07.10-20:09:48.95 - <debug> Initialized session 1
Initialized session with id: 1
2025.07.10-20:09:48.97 - <debug> Initialized resource 1
2025.07.10-20:09:48.98 - <debug> New rundir for resource 1: /run/user/1000/vaccel/73XJNT/resource.1
2025.07.10-20:09:49.19 - <debug> Downloading https://s3.nbfc.io/torch/mobilenet.pt
2025.07.10-20:09:55.17 - <debug> Downloaded: 816.6 KB of 13.7 MB (5.8%) | Speed: 137.30 KB/sec
2025.07.10-20:09:57.71 - <debug> Downloaded: 13.7 MB of 13.7 MB (100.0%) | Speed: 1.62 MB/sec
2025.07.10-20:09:57.73 - <debug> Download completed successfully
2025.07.10-20:09:57.87 - <debug> session:1 Registered resource 1
2025.07.10-20:09:57.88 - <debug> session:1 Looking for plugin implementing VACCEL_OP_IMAGE_CLASSIFY
2025.07.10-20:09:57.88 - <debug> Returning func from hint plugin torch
2025.07.10-20:09:57.88 - <debug> Found implementation in torch plugin
2025.07.10-20:09:57.88 - <debug> [torch] Loading model from /run/user/1000/vaccel/73XJNT/resource.1/mobilenet.pt
CUDA not available, running in CPU mode
2025.07.10-20:11:31.42 - <debug> [torch] Prediction: banana
classification tags: banana
classification imagename: PLACEHOLDER
2025.07.10-20:11:31.93 - <debug> session:1 Unregistered resource 1
2025.07.10-20:11:31.93 - <debug> Removing file /run/user/1000/vaccel/73XJNT/resource.1/mobilenet.pt
2025.07.10-20:11:31.94 - <debug> Released resource 1
2025.07.10-20:11:31.95 - <debug> Released session 1
2025.07.10-20:11:44.12 - <debug> Cleaning up vAccel
2025.07.10-20:11:44.12 - <debug> Cleaning up sessions
2025.07.10-20:11:44.12 - <debug> Cleaning up resources
2025.07.10-20:11:44.12 - <debug> Cleaning up plugins
2025.07.10-20:11:44.12 - <debug> Unregistered plugin torch
==1657==
==1657== HEAP SUMMARY:
==1657== in use at exit: 306,616 bytes in 3,294 blocks
==1657== total heap usage: 3,167,511 allocs, 3,164,217 frees, 533,893,229 bytes allocated
==1657==
==1657== LEAK SUMMARY:
==1657== definitely lost: 0 bytes in 0 blocks
==1657== indirectly lost: 0 bytes in 0 blocks
==1657== possibly lost: 0 bytes in 0 blocks
==1657== still reachable: 0 bytes in 0 blocks
==1657== suppressed: 306,616 bytes in 3,294 blocks
==1657==
==1657== For lists of detected and suppressed errors, rerun with: -s
==1657== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 3153 from 3153)
+ set +x
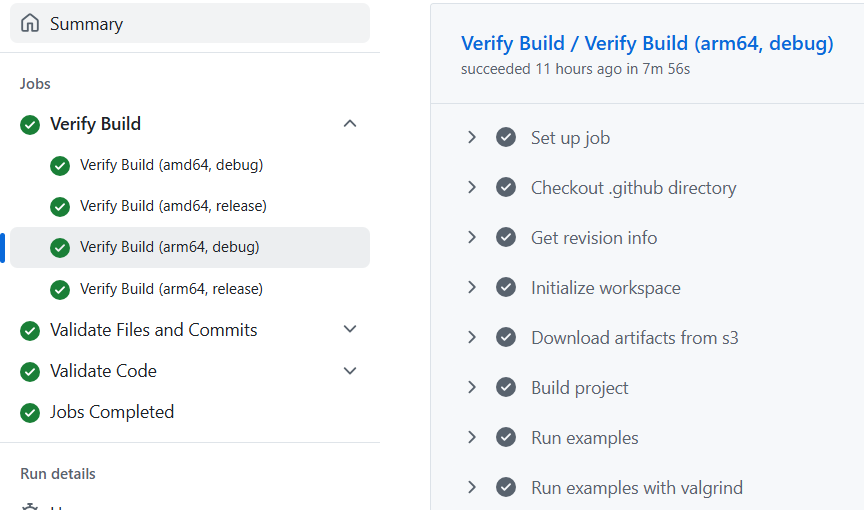
and the actual test in Figure 3, taking 8 minutes, almost 7 times faster than the original execution:
Wrapping Up
This experience was a great reminder that debugging tools and parallel
workloads don’t always play nicely, especially on less mature platforms.
Sometimes, the humble Raspberry Pi will leave a high-end chip in the dust,
at least when Valgrind is in the mix.
So next time you’re staring at a progress bar that refuses to budge, remember: more cores might just mean more waiting. And don’t be afraid to try your tests on the “little guy” – you might be surprised by what you find.